Данная страничка создана как пояснение к вопросу, который я задаю на форумах. Здесь собрано чуть больше информации по проблеме, чем можно удобно разместить на форуме.
Постановка вопроса
Как в Visual Studio C++ (версия не принципиальна) добиться правильного отображения в окне отладчика строк, написанных с использованием кириллицы? Комплект: Windows 7 US English + MS Visual Studio 2017.
Детали
Снимок экрана показывает суть проблемы:
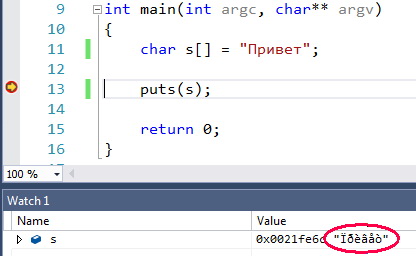
Немного о специфике проблемы:
Я знаю, что правильный ответ "использовать UNICODE, _T(), wchar_t и т.д.". Мне этот ответ не подходит, т.к. нужен именно 8-ми битный char по ряду причин:
- Задача требует обработки больших объёмов текстов и удвоение объёма занимаемой памяти сразу приведёт к потере производительности. Как минимум за счёт вылета из кэшей.
- Мне не хочется переписывать везде char на wchar_t, а также все другие типы (вида std::string) и вызовы API. Знаю, что это - единственно правильный путь и что только так можно работать с локализацией, но в данном случае хочется этого избежать.
- Есть большое количество кода, где используется 8-ми битный char в старых приложениях и его тоже порой надо отлаживать – поддержка, никуда не деться.
Я внимательно читал https://ru.stackoverflow.com/questions/459154/Русский-язык-в-консоли, Using UTF-8 as the internal representation for strings in C and C++ with Visual Studio и другие статьи, но они отвечают на другие вопросы.
В частности, мне не надо решать задачу правильного вывода на консоль – я понимаю, как это сделать. Меня интересует только правильное отображение в отладчике при использовании 8-ми битного char. Я хорошо понимаю, почему это не работает сейчас, но, наверное, возможно найти трюк, который мне поможет локально решить проблему?
Я рассматриваю возможность переписать шрифт, перенеся на место этих умляутов русские буквы, но, может быть, можно сделать как-то проще, сменив кодировку в Windows или как-то иначе?
Буду благодарен за любые советы. В данный момент вопрос размещён на форуме:
Также можно писать в почту damir_tenisheff@mail.ru.